Revolutionizing Web Migration
The power of site scraping tools
The world’s most trusted fitness brand, Life Fitness, approached the thunder::tech team in need of a complete website rebuild. But this wouldn’t be just any development project – the clock was ticking. Execution needed to occur quickly to avoid a costly recurring charge from their previous web service. Leaving this Software-as-a-Service (SaaS) web platform and shifting to Kentico would give Life Fitness more direct control over their site.
Content was a unique challenge for this project because of the volume. The previous platform account hosted 25 global sites, which they sought to combine into a single website. These sites hosted over 15,000 page-level entries, including products, product categories, markets, press releases, success stories and blog posts. So, how’d we do it?

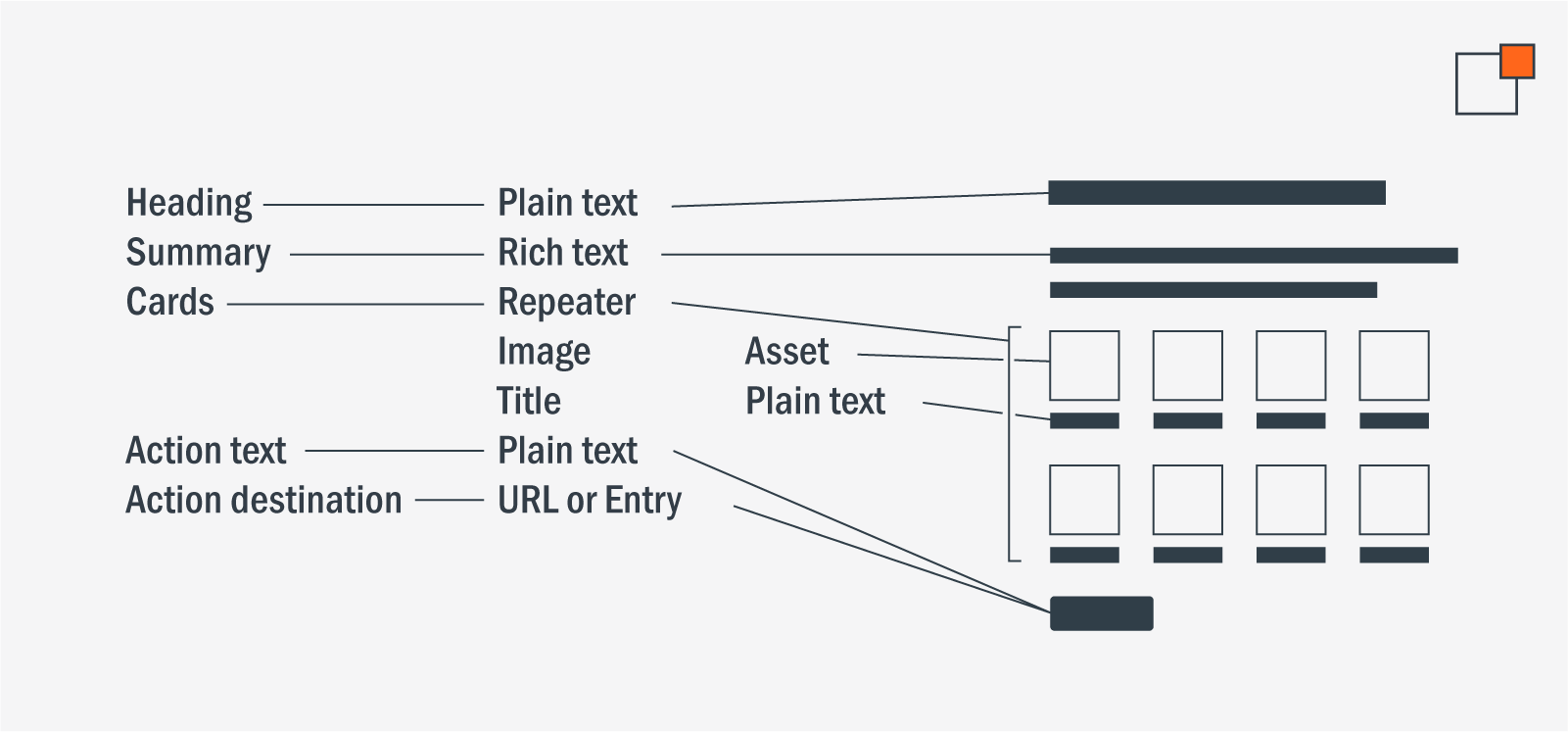 Content modeling definitions (left) with an example of how they might translate into a visual layout (right).
Content modeling definitions (left) with an example of how they might translate into a visual layout (right).
When a website undergoes a redesign, the designers frequently have the opportunity to reconsider how the content is structured. While it's feasible to revamp the visual appeal and arrangement without altering the modeling, restricting the content model could limit the potential for innovative design and marketing concepts.
Unfortunately, even with the technical hurdles of moving the content aside, 15,000 entries were far too many to restructure, rewrite and enter manually into a new system. Additionally, these 15,000 content entities, each with its own URL, do not even make up the entirety of the site's URLs, which amount to over 25,000. This alone made the choice: the content absolutely had to be migrated.
If the modeling differs, even slightly, that migration software must also precisely account for the differences and transform them as well. This was, therefore, not only a technical task but a strategic one. At a high level, there are two schemas layered on top of each other, one purely technical and one that is also strategic, on both the source and destination of the migration.
The unfamiliarity of the unique database organization of the previous web platform also posed a problem in writing a purely database-driven migration. To write a successful database-to-database migration, we had to thoroughly learn the previous system’s nuances, but there was limited time to do so.
Rather than writing an exporter in someone else’s language and schema, thunder::tech developed a tool that scrapes content off the front end of a site and organizes it into a predictable format for the importer. We call this tool the Content Migration Accelerator.
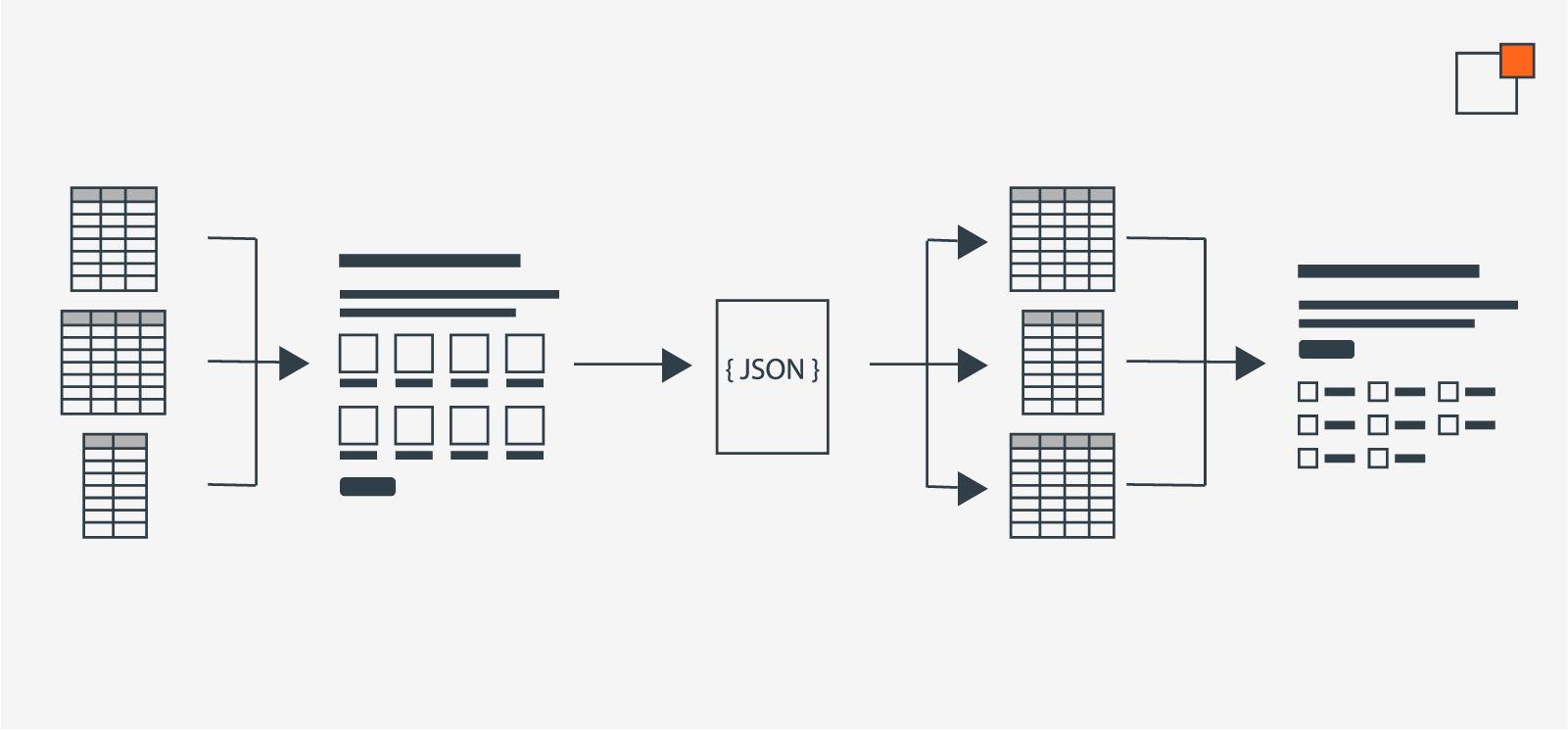 The original data format (left) is rendered into the previous site's user interface (second) which is scraped by the Content Migration Accelerator (third) and imported into the new site's database (fourth), finally used to render the updated interface design (right).
The original data format (left) is rendered into the previous site's user interface (second) which is scraped by the Content Migration Accelerator (third) and imported into the new site's database (fourth), finally used to render the updated interface design (right).
There are a few challenges to this method:
However, these challenges tend to be rare and are outweighed by the advantages of this method:
The obvious use case for this technology is migrating page-level content entries, but it excels at reading anything presented in a predictable structure, including sitewide content.
Entries may also retain some unique modeling attributes, such as a location and a date for an event or a price for a product.
Flexible components go by many names. In the WordPress content modeling plugin Advanced Custom Fields, the lists are called Flexible Content fields, and the types are called Layouts. In Kentico, the lists are called Widget Zones, and the types and instances are both called Widgets.
One advantage of the Content Migration Accelerator is that it can re-interpret the data it scrapes, turning fixed-entry modeling into flexible components or vice versa, depending on the plan for the new site. For the new Life Fitness website, the Content Migration Accelerator picked up over 103,000 component instances in 24 types from the previous site. From there, more interpretation was necessary to fit these into the new site’s organization, so our application developers wrote logic to filter, combine or split these instances into the content modeling of the new site.
The tool can be used to determine pages to scrape from other pages, such as a list of blog posts from a paged blog post list view. However, this is much less efficient than receiving a list of URLs to capture from a spider-like Screaming Frog.
The final consideration is that if your content modeling has changed, you’ll need a plan for how to map the old site’s modeling to the new site’s modeling. We’ll often recommend flexible components to migrate complex content without the bottlenecks of content modeling fixed to entry types.
Ready to revolutionize your website migration? Say goodbye to manual restructuring and embrace a more efficient, strategic approach. Your website's next chapter begins with cutting-edge content migration. Contact us today to get things started!
Content was a unique challenge for this project because of the volume. The previous platform account hosted 25 global sites, which they sought to combine into a single website. These sites hosted over 15,000 page-level entries, including products, product categories, markets, press releases, success stories and blog posts. So, how’d we do it?
Content modeling
When designing a website, part of that plan includes content modeling, a design representation of the content strategy that is structured and predictable enough to be represented in a database and used by the site’s programming to meaningfully display the stored content to the user. Content modeling is concerned with building a predictable structure around how individual pieces of information are grouped, repeated and related so that this structure can be applied to many content entries, navigating between the concerns of flexibility and scalability.Content modeling definitions (left) with an example of how they might translate into a visual layout (right). When a website undergoes a redesign, the designers frequently have the opportunity to reconsider how the content is structured. While it's feasible to revamp the visual appeal and arrangement without altering the modeling, restricting the content model could limit the potential for innovative design and marketing concepts.
Unfortunately, even with the technical hurdles of moving the content aside, 15,000 entries were far too many to restructure, rewrite and enter manually into a new system. Additionally, these 15,000 content entities, each with its own URL, do not even make up the entirety of the site's URLs, which amount to over 25,000. This alone made the choice: the content absolutely had to be migrated.
Database access and schemas
Still, with access to the client’s content database on the platform, there was far more complication to moving content over a database connection. Even if the content modeling was identical on the old and new systems, the way the database expresses that modeling was likely to be very different, and the old schema must be carefully translated to the new one by writing migration software.If the modeling differs, even slightly, that migration software must also precisely account for the differences and transform them as well. This was, therefore, not only a technical task but a strategic one. At a high level, there are two schemas layered on top of each other, one purely technical and one that is also strategic, on both the source and destination of the migration.
The unfamiliarity of the unique database organization of the previous web platform also posed a problem in writing a purely database-driven migration. To write a successful database-to-database migration, we had to thoroughly learn the previous system’s nuances, but there was limited time to do so.
A better solution
Luckily, we recently built a new tool to bypass this technical approach in most cases.Rather than writing an exporter in someone else’s language and schema, thunder::tech developed a tool that scrapes content off the front end of a site and organizes it into a predictable format for the importer. We call this tool the Content Migration Accelerator.
The original data format (left) is rendered into the previous site's user interface (second) which is scraped by the Content Migration Accelerator (third) and imported into the new site's database (fourth), finally used to render the updated interface design (right).There are a few challenges to this method:
- Any data not displayed on the existing site’s front-end can’t be scraped
- Underlying data relationships will get flattened into the related content without the references that generated them
- We rely on the previous site’s HTML to inform how data is structured, so poor HTML can create problems acquiring structure context
- All these challenges stem from the fact that the front-end of the site is presentational, meaning it wasn’t intended to convey data structures the way a database would.
However, these challenges tend to be rare and are outweighed by the advantages of this method:
- Pulling data is more efficient using our tool than writing a custom exporter because it eliminates complex steps involved in simple tasks.
- Strategic transformations in content modeling become even more efficient because our tool generates intermediate files that contain the data. This gives developers the opportunity to examine the content in a more straightforward form when writing the importer.
- Content that previously lacked a proper data structure, yet had its structure implied by HTML, can be transformed into structured data just as easily as content that was stored correctly.
The obvious use case for this technology is migrating page-level content entries, but it excels at reading anything presented in a predictable structure, including sitewide content.
Flexible components
Flexible components are a content modeling and development approach that unlocks the relationship between entry types such as products and success stories and content modeling. Rather than assigning a unique modeling to every entry type, entries are allowed a list into which they can place any number of component instances in any order. The component type then determines the fixed content modeling for that instance.Entries may also retain some unique modeling attributes, such as a location and a date for an event or a price for a product.
Flexible components go by many names. In the WordPress content modeling plugin Advanced Custom Fields, the lists are called Flexible Content fields, and the types are called Layouts. In Kentico, the lists are called Widget Zones, and the types and instances are both called Widgets.
One advantage of the Content Migration Accelerator is that it can re-interpret the data it scrapes, turning fixed-entry modeling into flexible components or vice versa, depending on the plan for the new site. For the new Life Fitness website, the Content Migration Accelerator picked up over 103,000 component instances in 24 types from the previous site. From there, more interpretation was necessary to fit these into the new site’s organization, so our application developers wrote logic to filter, combine or split these instances into the content modeling of the new site.
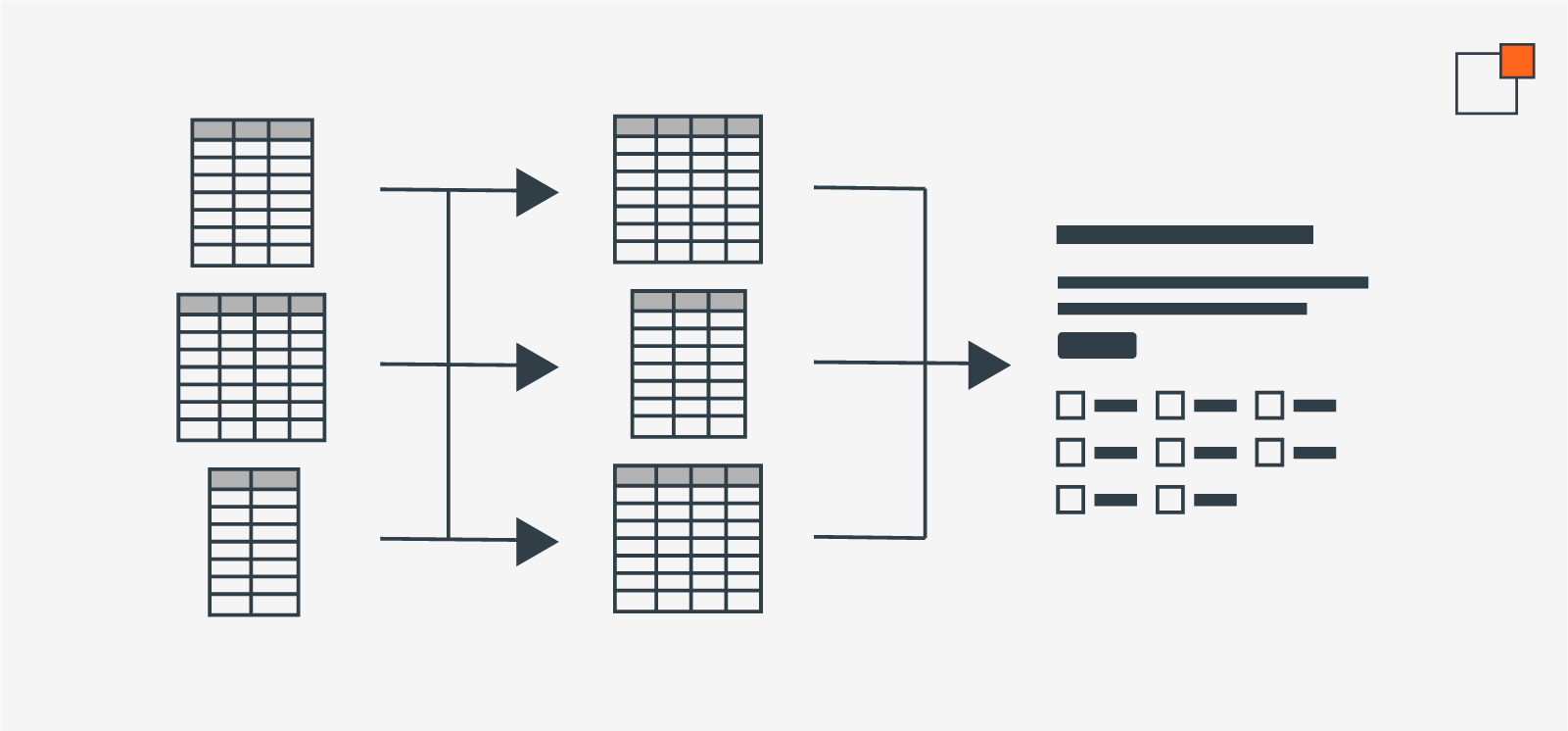 Without the Content Migration Accelerator, the previous site's database (left) has to be translated between data formats, likely unrelated to each other (center).
Without the Content Migration Accelerator, the previous site's database (left) has to be translated between data formats, likely unrelated to each other (center).
What to consider when migrating content this way
The Content Migration Accelerator is technically a bot, so web operations security systems may flag it as such. To prevent this from happening, typically clients will whitelist the IP addresses of the developers who are running the system.The tool can be used to determine pages to scrape from other pages, such as a list of blog posts from a paged blog post list view. However, this is much less efficient than receiving a list of URLs to capture from a spider-like Screaming Frog.
The final consideration is that if your content modeling has changed, you’ll need a plan for how to map the old site’s modeling to the new site’s modeling. We’ll often recommend flexible components to migrate complex content without the bottlenecks of content modeling fixed to entry types.
Ready to revolutionize your website migration? Say goodbye to manual restructuring and embrace a more efficient, strategic approach. Your website's next chapter begins with cutting-edge content migration. Contact us today to get things started!
